CSKS-(一)、数据结构和算法
算法复杂度
算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,算法的空间复杂度反映了程序执行时消耗的空间随输入规模增长而增长的规模;时间复杂度和空间复杂度在很大程度上能很好反映出算法的优劣。
在数学上有三个记号用于刻画算法复杂度:
- 大 $O$ 记号:表示函数数量级上的上界
- 大 $Ω$ 记号:与大 $O$ 记号相反,表示函数数量级上的下界
- 大 $Θ$ 记号:表示函数数量级上的一个确界
通常情况下主要考虑的是算法的最坏情况,即大 $O$ 记号。
数学定义
下面给出三个记号的数学定义:
若存在常量 $c$ 和函数 $f(n)$,对于任意的 $n \gg 2$,均有 $T(n) \le c \times f(n)$ 成立,则表示 $f(n)$ 给出了 $T(n)$ 增长的一个渐进上界,记作 $T(n) = O(f(n))$。
若存在常量 $c$ 和函数 $g(n)$,对于任意的 $n \gg 2$,均有 $T(n) \ge c \times g(n)$ 成立,则表示 $g(n)$ 给出了 $T(n)$ 增长的一个渐进下界,记作 $T(n) = \Omega(g(n))$。
若存在常量 $c1$、$c2$ 和函数 $h(n)$,对于任意的 $n \gg 2$,均有 $c1 \times h(n) \le T(n) \le c2 \times h(n)$ 成立,则表示 $h(n)$ 给出了 $T(n)$ 增长的一个渐进下界,记作 $T(n) = Θ(h(n))$。
P 问题和 NP 问题
一般地,$O(log_2n)$、$O(n)$、$O(n \times log_{2}n)$、$O(n^2)$、$O(n^3)$ 称为多项式复杂度;$O(2^n)$、$O(n!)$ 称为指数复杂度。
计算机科学家普遍认为前者(即多项式时间复杂度的算法)是有效算法,把这类问题称为 P(Polynomial,多项式)类问题,而把后者(即指数时间复杂度的算法)称为 NP(Non-Deterministic Polynomial,非确定多项式)问题。
多项式复杂度用于求解问题的代价是可接受的。很多问题没有多项式时间的解,比如大数分解、Hamilton 回路。虽然这些问题没有多项式时间内的解,但是可以在多项式时间内验证某个猜想是否正确。
References
数据结构
数组、链表、栈、队列等是数据结构中最常用的,且实现比较简单。
References
并查集
并查集这个数据结构主要用于判断两个元素是否为同一个集合元素。这里以 p[i] 表示 i 元素所在集合,开始时每个元素各占一个集合;union(i, j) 操作将原有两个集合 i、j 合并为一个集合。
void init() {
for (int i = 0; i < n; ++i) p[i] = i;
for (int i = 0; i < n; ++i) weight[i] = 1;
}
int find(int i) {
while (i != p[i]) i = p[i];
return i;
}
void union(int x, int y) {
int i = find(x);
int j = find(y);
if (i == j) return;
if (weight[i] < weight[j]) { p[i] = j; weight[j] += weight[i]; }
else { p[j] = i; weight[i] += weight[j]; }
}
init()用于初始化并查集find()用于找到当前元素所在的集合union()用于将两个元素的集合合并起来
因为使用类似与子节点指向父节点的原理,如果合并中一直加到某个节点最下方,将导致链变长。因此使用 weight 记录集合权重,每次将权重小的集合加到权重大的集合后,加快了 find 的速度。
优先队列
优先队列内部由堆构成,堆类似二叉树,其中子节点均小于父节点。只要保证每次插入、删除数据时保持堆原有的性质,那么可以在 $O(1)$ 的时间复杂度内得到最小(最大)值。
References
树
二叉树
二叉树是指最多有两个孩子节点的树。在计算机科学中,二叉树有几个重要的性质:
- 二叉树第 $i$ 层最多有 $2^{i-1}$ 个节点,其中 $i \ge 1$
- 二叉树深度为 $k$,那么最多有 $2^k-1$ 个节点,其中 $k \ge 1$
- $n_0$ 表示度为 $0$ 的节点,$n_2$ 表示度为 $2$ 的节点,那么有 $n_0=n_2+1$
- 在完全二叉树中,具有 $n$ 个节点的二叉树深度为 $\lfloor log_2(n + 1) \rfloor + 1$
第一个可以不用证明。以 $l_i$ 表示第 $i$ 层有最多有多少个节点,那么第二条结论等于 $total=l_1+l_2+\cdots+l_k=1+2+\cdots+2^{i-1}=2^i-1$。
第三个性质需要用到其他两个公式:
- $n=n_0+n_1+n_2$ $n$ 表示总节点个数,$n_1$ 表示度为 $1$ 的节点的个数
- $n-1=2n_2+n_1$ 这个公式是边的数量的恒等式
两式相减可以得到第三条公式。
完全二叉树最后一层长度为 $1 \to 2^{i-1}$ 之间,因为 $2^i-1=n$,所以成立。
References
二叉查找树
假设有这样一颗二叉树,其节点值保存一个数据,而左节点的值均小于等于当前结点,右节点所有值均大于等于当前节点,那么这棵树就叫做二叉查找树。
在查找时,类似与二分查找,先判断是否等于当前值,然后根据大小在左右两侧进行查找。当然,因为没有其余限制,极端情况下二叉查找树会形成一条链,此时查找时间便降到 $O(n)$。所以实际使用中会对二叉查找树进行旋转操作,进行旋转的二叉查找树被成为平衡二叉树。比起普通二叉树,平衡二叉树在实现上复杂得多。
References
AVL 树
AVL 树是一种平衡二叉查找树,也被称为高度平衡树。它的特点是任何两个节点的高度差最大为 $1$。
如果树有 $n$ 个节点,AVL 树的增删查改操作复杂度为 $log(n)$,如果插入、删除操作导致 AVL 树中某个节点不再满足上述性质,那么平衡状态就被破坏。所以要对其进行旋转操作,保证其平衡性。
AVL 树只有四种可能出现的不平衡状态,与之对应的,就是 $4$ 种旋转操作。
References
另一种二叉查找树是伸展树,伸展树有一个特点:当某个节点被访问时,伸展树会通过旋转操作使得该节点成为树根。所以再次访问这个节点时,能够迅速访问到这个节点。更多伸展树相关的请看伸展树。
红黑树
References
Tire 树
References
B 树
References
区间信息维护与查询
有时会需要在区间上进行操作,比如区间最值、区间和等。
树状数组
树状数组提供了一种查询和维护区间和的方式。
low_bit
进一步将树状数组前,得讲讲 low_bit,low_bit 用于求出数值二进制表示中的最后一个 $1$ 所表示的数值。
int low_bit(int c) {
return c & (c ^ (c - 1));
}
从二进制的角度可以清晰地观察到原理:
以 15(1110) 为例,15-1(1101),15^(15-1)(0011),所以
low_bit(15)(0010)
树状数组用 $c[i]$ 记录 $a[i-low_bit(i)+1]+…+a[i]$ 的信息。那么想要前 $i$ 个数据的和就可以用下面的代码:
int sum(int i) {
int ret = 0;
while (i > 0) {
ret += c[i];
i -= low_bit(i);
}
return ret;
}
可以看到前 $i$ 个数据和为 $a[1]+a[2]+…+a[i]$,将其划分为两部分 $a[1]+a[2]+…+a[i-low_bit(i)]$ 和 $a[i-low_bit(i)+1]+…+a[i]$,后一部分等价于 $c[i]$。现在就将求和转换为求前 $i-low_bit(i)$ 项加上 $c[i]$ 的和。递归地运用,就能得到具体值。
树状数组同时还允许修改操作:
void add(int i, int d) {
while (i <= length) {
c[i] += d;
i += low_bit(i);
}
}
这里算法将等价于执行a[i] += d,其中length为数据长度最大值。当修改了元素值后,树状数组维护的信息也应修改。因为 $c[i]$ 等于 $a[i-low_bit(i)+1]+…+a[i]$,而 $c[i+low_bit(i)]$ 的区间范围为:$[i+low_bit(i)-low_bit(i+low_bit(i))+1, i+low_bit(i)]$,其中 $low_bit(i+low_bit(i))$ 显然等于 $low_bit(i) « 1$,所以等价于 $[i-low_bit(i)+1, i+low_bit(i)] > [i-low_bit(i)+1, i]$。要保证树状数组信息正确,必须在修改 $c[i]$ 后同时修改 $c[i+low_bit(i)]$ 所在值。
有了两个操作后,就能完成区间查询操作,比如查询[3,5]的和,可以使用 $sum(5)-sum(2)$。
当然,树状数组需要进行初始化,如何初始化?使用add(i, a[i])。可以简单得出树状数组初始化操作耗时 $O(n \times log_2n)$,查询操作耗时 $O(log_2n)$。
线段树
树状数组适合查询区间值。其主要思想是在数据集上维护一颗二叉树,二叉树叶子节点对应一个具体数据,而父节点表示左右节点对应的集合。
[1,4]
[1,2][3,4]
[1][2][3][4]
如上所示,最下方为其数据集,而上方为对应的父节点。现在用每个父节点维护其子节点对应区间的信息(最大值、最小值、求和)。那么如果要查询某个区间内容比如 [1,3],可以将集合分为 [1,2][3] 两部分,因此每次查询会停留在区间被完全覆盖的节点上,从而实现快速查询。
同树状数组一致,当更新某个数据时,同样需要更新其上方包含该区间的节点的信息。线段树还可以对一个区间进行快速操作,比如整个区间加上某个值。实现方式很简单,在每个节点处加上一个额外的信息,在进行操作时,如果区间完整覆盖了当前区间,那么就把操作添加到当前额外信息上。当然,后续查询中如果查到的区间小于该节点的区间怎么办?那就需要把额外信息往下传递。
Sparse Table
如果仅仅需要查询区间最值,且初始化后数据不会改变,那么使用 sparse table 是不错的选择。
sparse table 的思路是使用函数 $f(i, j)$ 表示从 $i$ 开始长度为 $2^j$ 的一段元素中的最小值(最大值)。显然有 $f(i, j)=min(f(i, j-1), f(i+2^{j-1}, j-1))$ 成立。观察到总共有 $n$ 个数据,而每个数据表示长度最多为 $log(n)$,所以总共初始化耗时 $O(n \times log_2(n))$。
void init(int *a, int n) {
for (int i = 0; i < n; ++i) d[i][0] = a[i];
for (int j = 1; (1 << j) <= n; ++j) {
for (int i = 0; i + (1 << j) - 1 < n; ++i)
d[i][j] = min(d[i][j-1], d[i+(1<<(j-1))][j-1]);
}
}
当构造好了 table 后如何查询呢?比方说想要找到区间 $[L, R]$ 的最值,这时需要找到一个区间满足$2^k \le R-L+1$,其中 $k$ 为满足前面不等式的最大整数,那么就可以通过区间 $[L, L+2^k]$ 和 $[R-2^k+1, R]$ 的最值进行比较得到(即 $f(L, k)$ 和 $f(R-z^k+1, k)$,因为求最值,所以区间重叠不影响结果)。
int query(int l, int r) {
int k = 0;
while (1 << (k+1) <= r-l+1) k++;
return min(d[l][k], d[r-(1<<k)+1][k])
}
完成预处理后,查询操作可以在常量时间内完成。
排序算法
这里列出了常见的十大排序算法
| 算法 | 空间 | 稳定 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 冒泡排序 | in | stable | $O(n^2)$ | - |
| 插入排序 | in | stable | $O(n^2)$ | - |
| 选择排序 | in | unstable | $O(n^2)$ | $O(1)$ |
| 归并排序 | out | stable | $O(nlog(n))$ | $O(n)$ |
| 快速排序 | in | unstable | $O(n^2)$ | - |
| 堆排序 | in | unstable | $O(nlog(n))$ | - |
| 计数排序 | out | stable | $O(n+k)$ | - |
| 桶排序 | out | stable | $O(n^2)$ | - |
| 基数排序 | out | stable | $O((n+k)d)$ | - |
| 希尔排序 | - | - | - | - |
解释:
- stable:表示排序前后值相同的元素相对位置不变
- unstable:与上面相反
- In-place:表示排序算法可以在原有数据空间上执行
- Out-place:表示排序算法需要额外的空间来执行
冒泡排序
冒泡排序是通过两两交换,像水中的泡泡一样,小的先冒出来,大的后冒出来。具体实现为:从第一个到最后一个扫描,每次按一定顺序排列相邻的两个元素;执行一次后,找到一个最大元素,将查找范围减一后重复执行上一部;执行多次后,达到有序。
for (int i = length-1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (a[j] > a[j+1])
swap(a, j, j + 1);
}
}
插入排序
插入排序将数据分为前后两个部分:
- 按照某种顺序有序部分
- 无序部分
每次将无序部分的第一个数据与有序部分进行比较并交换,这样朝着开始方向移动,直到找到第一个大于或小于该数据的值。
插入排序比较适合用于“少量元素的数组”。其实插入排序的复杂度和逆序对的个数一样,当数组倒序时,逆序对的个数为 $\frac{n(n-1)}{2}$,因此插入排序复杂度为 $O(n^2)$。
for (int i = 0; i < length; ++i) {
for (int j = i; j > 0 && less(a[j], a[j-1]); j--)
swap(a, j, j-1);
}
插入排序的速度直接是逆序对的个数,而冒泡排序中执行“交换“的次数是逆序对的个数,因此冒泡排序执行的时间至少是逆序对的个数,因此插入排序的执行时间至少比冒泡排序快。
选择排序
每次找一个最小值。具体实现为每次在未排序数据中找到一个最值,并加到以排序数据首部或尾部。
for (int i = length - 1; i >= 0; i--) {
int idx = i;
for (int j = 0; j < i; j++) {
if (a[idx] < a[j])
idx = j;
}
swap(a, i, idx);
}
归并排序
运用分治法思想解决排序问题。实现中将原有数据分为两个部分,递归调用自己,最后得到了两份有序的数据,然后将两份有序数据合并。
// [l, r)
void sort(int *a, int *tmp, int l, int r) {
if (l >= r-1)
return;
int mid = l + (r - l) / 2;
sort(a, tmp, l, mid);
sort(a, tmp, mid, r);
int i = l, j = mid, k = 0;
for (int k = 0; k < r - l; k++) {
if (i < mid) tmp[k++] = a[i++];
else if (j > hi) tmp[k++] = a[j++];
else if (a[i] > a[j]) tmp[k++] = a[j++];
else tmp[k++] = a[i++];
}
for (int k = 0; k < r - l; k++)
a[l + k] = tmp[k];
}
归并排序是 out-place sort,与快速排序相比,需要很多额外空间;通常情况下,归并和快排渐进复杂度一致,不过归并排序系数大于快排,所以通常认为归并排序慢于快排。
插入排序适合对小数组进行排序,所以可以使用插入排序对归并排序进行改进。以数组长度为 $k$ 时采用插入排序,则渐进复杂度为 $O(nk+nlog(n/k))$,如果保证 $k=log(n)$,那么有 $O(nlog(n))$。
快速排序
快速排序的思想也是分治法。具体做法是选择一个元素作为 pivot,并用 pivot 将数据分为大于 pivot 和小于 pivot 的两部分。然后分别对这两部分递归调用自己,此时得到的数据便是有序的。
在数组已经有序时,快排的时间复杂度为 $O(n^2)$。通常使用随机化(shuffle array 或者 randomized select pivot)来改进,使得期望运行时间为 $O(nlog(n))$。
当输入数组的所有元素都一样时,不管是快速排序还是随机化快速排序的复杂度都为 $O(n^2)$,使用三向切分技术可以使这种情况下的复杂度为 $O(n)$。
// [l, r)
int partition(int *a, int l, int r) {
int lt = l, gt = r;
int pivot = a[l];
while (true) {
while (a[++lt] < pivot) if (lt >= r) break;
while (pivot < a[--gt]) if (gt <= l) break;
if (lt >= gt) break;
swap(a, lt, gt);
}
swap(a, gt, l);
return gt;
}
// [l, r)
void sort(int *a, int l, int r) {
if (l >= r-1)
return;
int part = partition(a, l, r);
sort(a, l, part);
sort(a, part + 1, r);
}
在算法一书中还介绍了一种快排的优化算法:三向切分。其核心思想是将原有的分成两部分转换为分成三部分:小于、等于、大于。具体实现需要依赖于下面的数据(以递增排序为例):
lt表示当前不小于pivot的第一个元素i表示未排序的第一个元素gt表示大于pivot的第一个元素
根据上面的,分析过程中数据布局如下:
[l 小于pivot |lt 等于pivot |i 未排序 |gt 大于pivot r)
此时选中第一个i进行操作:
- 如果 $a[i] == pivot$ 则 $i=i+1$
- 如果 $a[i] > pivot$ 则交换 $a[–gt]$ 和 $a[i]$
- 如果 $a[i] < pivot$则交换 $a[i++]$ 和 $a[lt++]$
每次操作完成后,仍然保持了原有的数据格式。重复该过程直到$i==gt$ 则表示 partition 操作完成,现在只需要对 $[l, lt)$ 和 $[gt, r)$ 部分进行排序即可。
void sort(int *a, int l, int r) {
if (l >= r-1)
return;
int lt = l, i = l+1, gt = r;
int pivot = a[l];
while (i < gt) {
int cmp = a[i] - pivot;
if (cmp > 0) swap(a, --gt, i);
else if (cmp < 0) swap(a, i++, lt++);
else i++;
}
sort(a, l, lt);
sort(a, gt, r);
}
堆排序
运用了最小堆、最大堆这个数据结构,而堆还能用于构建优先队列。
References
计数排序
计数排序有很大的局限性,其要求数据范围比较小,能枚举。具体实现思路是将其按照数据数据大小,直接分配一个固定位置。
一般情况下计数排序复杂度为 $O(n+k)$,当$k=O(n)$时,计数排序时间为$O(n)$,其中 $k$ 表示数据范围,$n$ 表示数据长度。
void sort(int *a, int n, int k) {
int b[n+1], c[k+1];
for (int i = 0; i <= k; ++i) c[i] = 0;
for (int i = 1; i <= n; ++i) c[a[i-1]]++;
for (int i = 1; i <= k; ++i) c[i] += c[i-1];
for (int i = n; i > 0; --i) b[c[a[i-1]]--] = a[i-1];
for (int i = 0; i < n; ++i) a[i] = b[i+1];
}
桶排序
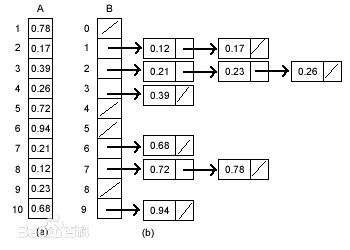
算法:将元素按照范围依次分散到多个桶中,此时桶的范围是有序的。再对每个桶进行排序,最后得到的数据就是有序的。
当分布不均匀时,全部元素都分到一个桶中,则 $O(n^2)$,当然也可以将插入排序换成堆排序、快速排序等,这样最坏情况就是 $O(nlog(n))$。
void sort(int *a, int n) {
int *b[10] = { 0 };
int l[10] = {0};
for (int i = 0; i < n; ++i) {
int idx = a[i] % 10;
将a[i]插入到b[idx]中
l[idx]++;
}
for (int i = 0; i < 10; ++i)
otherSort(b[i], l[i]);
}
桶排序的缺点是:
- 首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从 $0$ 到 $m-1$,那就需要 $m$ 个桶,这个桶数组就要至少 $m$ 个空间。
- 其次待排序的元素都要在一定的范围内等等。
基数排序
这里假定每位的排序是计数排序。而计数排序是稳定的,所以对部分有序的数据排序,得到的结果仍然满足部分有序。话句话说,如果第 $k+1$ 位有序,对第 $k$ 位进行计数排序后,得到的结果仍然在 $k+1$ 位有序。将原有数据每一位依次排序,最后得到的结果能保证有序。
计数排序复杂度为 $O((n+k)d)$。
- $d$ 表示位数
- $k$ 表示数据范围
- $n$ 表示长度
当 $d$ 为常数、$k=O(n)$时,效率为$O(n)$。
// 其中counter用于对第i位排序
void sort(int *a, int d, int n) {
for (int i = 1; i <= d; ++i) {
counter_sort(a, i, n);
}
}
希尔排序
希尔排序是利用插入排序在有序时速度快的特点。以 $k$ 为间隔对数据进行排序,直到 $k=1$。
void sort(int *a, int n) {
int k = 0;
while (k < n/3) k = k*3 + 1;
while (k >= 1) {
for (int i = k; i < N; ++i) {
for (int j = i; j >= k && a[j] < a[j-k]; j -= k)
swap(a, j, j-k);
}
k /= 3;
}
}
查找
查找算法
二分查找
对于有序且可以随机访问的数据,要判断数据中是否含有某个值,可以使用 $O(log(n))$ 的二分查找。
对于一个给定的区间 $[l, r)$,我们判断 $mid=\frac{l+r}{2}$ 是否为目标值,是表示找到,否则没有找到。没有找到时,判断值和 $val[mid]$ 和目标值的大小,如果目标值小于中间值,则实际值应该能在左边区间 $[l, mid)$ 中找到,否则应该在 $[mid + 1, r)$ 中查找。
// [l, r)
int search(int *a, int n, int val) {
int l = 0, r = n;
while (l < r) {
int mid = l + (r-l)/2;
if (a[mid] < val) r = mid;
else if (a[mid] > val) l = mid + 1;
else return mid;
}
return -1;
}
三分查找
二分查找适用于单调函数中逼近求解某点的值。如果遇到凸性或凹形函数时,可以用三分查找求那个凸点或凹点。
假设我们要找一个凸点,给了区间 $[l, r]$ 和函数 $f(x)$,下面找出中点 $mid=(l+r)/2$,以及 $[mid,r]$ 的中点 $mmid=(mid+r)/2$。通过比较 $f(mid)$ 与 $f(mmid)$ 的大小来缩小范围,当最后 $L=R-1$ 时,再比较下这两个点的值,我们就找到了答案。
当 $f(mid) > f(mmid)$ 的时候,我们可以断定 $mmid$ 一定在最值点的右边。假设 $mmid$ 在最值点的左边,则 $mid$ 也一定在最值点的左边,又由 $f(mid) > f(mmid)$ 可推出 $mmid < mid$,与已知矛盾,故假设不成立。所以,此时可以将 $R = mmid$ 来缩小范围。
当 $f(mid) < f(mmid)$ 的时候,我们可以断定 $mid$ 一定在最值点的左边。反证法:假设 $mid$ 在最值点的右边,则 $mmid$ 也一定在最值点的右边,又由 $f(mid) < f(mmid)$ 可推出 $mid > mmid$,与已知矛盾,故假设不成立。同理,此时可以将 $L = mid$ 来缩小范围。
int search(int l, int r) { //找凸点
while (l < r-1) {
int mid = (l+r)/2;
int mmid = (mid+r)/2;
if (f(mid) > f(mmid))
r = mmid;
else
l = mid;
}
return f(l) > f(r) ? l : r;
}
树
树已经在前面数据结构-树中介绍了。
Hash
散列表
散列表类似于数组的使用方式,通过 key 找到对应的 value。使用散列查找算法分为两步:
- 用散列函数将
key映射到数组的索引上 - 处理索引(hash)冲突
散列函数选取非常重要,因为好的散列函数能够将数据均匀的分布在数组上。这里重点看冲突的处理,冲突处理主要有两种方式:
- 链地址法
- 线性探测法(开放地址法)
在散列表使用中,由于冲突的存在,散列表除了要保存value外,也要保存key。查找时,需要对 key 进行比对,成功时才是真正定位到了具体数据上。
链地址法将数组看作一个个桶,具体的数据通过链表链接到桶后。java 中的 HashMap 便是使用的链地址法。而线性探测法是发生冲突时重新选择一个新的 hash 值作为索引,直到找到空位为止。
当散列表中存储数据到达一定限制后,就要调整散列表大小。比如线性探测法中,如果 存储键的数目N=数组大小M,那么永远也找到一个新的空位存放当前元素。这里需要介绍负载因子(load factor),表示散列表空间使用率。在 HashMap 中的负载因子默认为 0.75,桶的大小M*loadFactor 得到容量调整的 阈值(threshold)。所以当 键的数量N大于桶大小M*0.75 后, HashMap 会调整容量大小。具体调整多少呢?在 Java 中默认是两倍,因为散列表桶大小默认是16,而 HashMap 又使用 hash 值模上桶大小比如 key.hashcode() & (length - 1) 作为桶索引。(只有在 length 为2的倍数时,& 结果和 % 结果一致,如果将容量扩充为其他数量而非2的倍数,那么 & 得到的索引值可能就不是均匀的分布在数组上了)。
References
Hash 树
在 Hash 表中通常使用素数作为模运算的因子,对于一个 Hash 值,如果素数为 $x$,那么能将 Hash 值域分为 $x$ 块。再这个基础上,再做一次取模,如果用素数 $y$ 且 $y \ne x$,那么就将值域分为了 $x \times y$ 块。依次类推,形成一颗树状的表,称为 Hash 树。
References
图
图由顶点(vertex, node)和边(edge)组成。假设定点集合为 V,边集合为 E,那么图可以表示为 G(V, E),连接两点 u 和 v 的边用 e(u, v) 表示。图分为有向图和无向图,分别表示边是否有指向性。实际应用中,还会给边赋予各种各样的属性。比较具有代表性的有权值(cost),此时称图为带权图。
图的术语
对于无向图,两个定点之间如果有边连接,那么就认为两点相邻。相邻定点的序列称为路径。起点和终点重合时,路径被称为圈。任意两个点都存在路径的叫做连通图。定点的边数叫做这个顶点的度。我们称没有圈的连通图为树,没有圈的非连通图为森林。对于树,边数正好等于顶点数减一,这是一个等价条件。
对于有向图,起点为顶点 V 的边为 V 的边集。边集数目等于定点出度,重点为定点V的边的数目等于定点的入度。如果有向图没有圈,那么该图称为DAG(Directed Acyclic Graph)。
图的表示方法
图常见的表示方法有两种:
- 邻接矩阵;
- 邻接表。
| 两种方法各有优缺点,适合不同的算法。接下来,记顶点和边的集合为 V 和 E , | V | 和 | E | 分别表示顶点和边的个数,另外,将顶点编号为 $0 \cdots | V | -1$。 |
| 邻接矩阵使用 $ | V | \times | V | $ 的二维数组来表示图,其中 $g[i][j]$ 表示顶点 $i$ 和顶点 $j$ 的关系,比如是否连接,或者边的权值。需要注意的是,如果图存在重边或者自环,如果使用的是无权图,那么用 $g[i][j]$ 表示边数即可,对于带权图则无法表示。同时,对于稀疏图,会存在这大量浪费空间的情况,比如表示一颗树,只需要记录 $ | V | -1$ 条边,而实际上花费了 $ | V | * | V | $ 的空间。 |
| 使用邻接表则完美解决上述情况,邻接表将边保存到对应的顶点处,向链表一样,指向其他顶点。使用邻接表只需要花费 $O( | V | + | E | )$的空间。 |
// 邻接表表示
struct vertex {
vector<vertex*> edge;
//顶点属性
};
vertex G[Nodes];
// or
struct edge {
int from, to, cost;
};
vector<edge> G[Nodes];
拓扑排序
References
联通分量
强连通分量
References
双联通分量
References
最近公共祖先
References
2-SAT
References
最短路径
所谓最短路径,是指给定两个顶点,找到以这两个顶点为起点和重点的路径中,边权值最小的路径。而单源最短路径则是固定一个顶点,求该点到其他所有定点的最短路的问题。
单元最短路径的算法有两种:1、Bellman-ford;2、Dijkstra 。
Bellman-ford
| 记从顶点 $s$ 出发,到顶点 $i$ 的最短距离为 $d[i]$,那么有:$d[i]=min(d[j]+weight(j, i) | e(j,i) \in E)$ 成立。 |
struct edge { int from; int to; int cost; };
edge es[MAX_E];
int d[MAX_V];
int V, E;
void bellman_ford(int s) {
for (int i = 0; i < V; ++i) d[i] = INF;
d[s] = 0;
while (true) {
bool update = false;
for (int i = 0; i < E; ++i) {
edge e = es[i];
if (d[e.from] != INF && d[e.to] > d[e.from] + e.cost) {
d[e.to] = d[e.from] + e.cost;
update = true;
}
}
if (!update) break;
}
}
| 上面的方法就叫做 Bellman-ford 算法,如果图中不存在从点 $s$ 可达的负圈,那么路径一定不会经过任一点两次,所以最外层循环最多执行 $ | V | -1$ 次。所以总的时间复杂度为 $ | V | \times | E | $。如果存在负圈,那么 $ | V | $ 次一定还会更新 $d$ 的值,所以可以用此判断是否有负圈。 |
Dijkstra
如果图中不存在负权边,那么可以用 Dijkstra 算法来求单源最短路径。在 Bellman-ford 算法中,如果 $d[j]$ 不是点 $j$ 到起点的最短路径,那么 $d[i]=d[j]+cost(j,i)$ 自然得到的也不是最短路径。而 Dijsktra 算法正好解决了这个问题,它将顶点分为两部分,一部分已经找到了最短距离,另一部分没找到。每次计算时,在还不是最短距离的集合中找到最短的那条,加到已经找到的集合中去。
那么如何更新距离呢?实际上只需要找到未使用过的顶点中的某个 $j$,和已经最短的顶点 $i$,保证 $d[i]+cost(i, j)=d[j]$ 比其余顶点都短,那么得到的 $d[j]$ 就是 $s$ 到 $j$ 的最短路径。
struct edge { int to, cost; };
typedef pair<int, int> P;
int V, E;
vector<edge> G[MAX_V];
int d[MAX_V];
void dijkstra(int s) {
priority_queue<P, vector<P>, greater<P>> que;
fill(d, d+V, INF);
d[s] = 0;
que.push(P(0, s));
while (!que.empty()) {
P p = que.top(); que.pop();
int v = p.second;
for (int i = 0; i < G[v].size(); ++i) {
edge e = G[v][i];
if (d[e.to] > d[v] + e.cost) {
d[e.to] = d[v] + e.cost;
que.push(P(d[e.to], e.to));
}
}
}
}
| 上面的算法在每次循环中,找出已经找到最短路径中距离 $s$ 点最短的点,然后更新与该点相邻的点的距离。这个算法的复杂度是 $O( | E | \times log( | V | ))$。 |
Floyd-Warshall
| 求解所有两点间的最短路的问题叫做任意两点间的最短路问题。Floyd-Warshall 算法可以在 $ | V | \times | V | \times | V | $ 的时间里求得所有点的最短路径长度,同 Bellman-Ford 算法一样,可以处理负边的情况。该算法主要利用公式:$d[i][j]=min(d[i][j], d[i][k]+d[k][j])$ 的不断更新来实现。 |
int d[MAX_V][MAX_V];
int V;
void warshall_floyd() {
for (int k = 0; k < V; ++k)
for (int i = 0; i < V; ++i)
for (int j = 0; j < V; ++j)
d[i][j] = min(d[i][j], d[i][k]+d[k][j]);
}
最小生成树
给定一个图,在图上找到一棵树,那么这棵树被称为生成树。如果树的边权是所有树中最短的,这棵树被称为最短生成树。最小生成树求解有两种算法。
Prim
Prim 算法和 Dijkstra 算法类似,均是从一个顶点出发,不断地添加边的算法。具体思路是假设一颗只包含一个顶点 $v$ 的树 $T$,然后贪心地选取 $T$ 和其他顶点之间相连的权值最小的边,并把它加到 $T$ 中。不断的进行该操作,直到所有节点均在 $T$ 中。其复杂度为 $O(V*V)$:
int cost[MAX_V][MAX_V];
int mincost[MAX_V];
bool used[MAX_V];
int V;
int prim() {
for (int i = 0; i < V; ++i) {
mincost[i] = INF;
used[i] = false;
}
mincost[0] = 0;
int res = 0;
while (true) {
int v = -1;
for (int u = 0; u < V; u++) {
if (!used[u] && (v == -1 || mincost[u] < mincost[v])) v = u;
}
if (v == -1) break;
used[v] = true;
res += mincost[v];
for (int u = 0; u < V; u++) {
mincost[u] = min(mincost[u], cost[v][u]);
}
}
return res;
}
Kruskal
| Kruskal 算法是按照边的权值的顺序从小到大看一遍。Kruskal 在边的排序上最花时间,算法复杂度为 $O( | E | \times log( | E | ))$。Kruskal 使用并查集,每次找到未使用的最小的边时,首先判断是否在一个集合。在一个集合就啥也不做,否则就把两者所在的集合合并。 |
struct edge { int u, v, cost; };
bool comp(const edge &e1, const edge &e2) {
return e1.cost < e2.cost;
}
edge es[MAX_E];
int V, E;
int kruskal() {
sort(es, es + E, comp);
init_union_find(V);
int res = 0;
for (int i = 0; i < E; i++) {
edge e = es[i];
if (!same(e.u, e.v)) {
unite(e.u, e.v);
res += e.cost;
}
}
return res;
}
二分图匹配
References
网络流
References
数学
最大公约数
求解最大公约数问题可以使用辗转相除法。辗转相除法实际上由一个等价公式推出:$gcd(a, b)=gcd(b, a \mod b)$,代码如下:
int gcd(int a, int b) {
if (b == 0) return a;
return gcd(b, a % b);
}
最小公倍数
最大公约数与最小公倍数在数学上存在联系:$lcm(a, b) = \dfrac{a \times b}{gcd(a, b)}$ 。只要计算出 $gcd(a, b)$,通过上式可计算 $lcm(a, b)$。
素数判断
恰好有两个约数的整数被称为素数。如果 $d$ 是数 $n$ 的约数,那么 $\dfrac{n}{d}$ 也是 $n$ 的约数。因此只需要检查 $2 \to \sqrt{n}$ 范围内的整数就够了。
bool is_prime(int n) {
for (int i = 2; i * i <= n; ++i) {
if (n % i == 0) return false;
}
return true;
}
这个算法适合查询一次,如果查询多次,有另一种办法。埃氏筛法可以枚举 $n$ 以内的素数,其主要思路是将 $2 \to n$范围内的数据都写下来。其中最小的数字是 $2$,然后将所有 $2$ 的倍数全部删去。依次类推,将剩余的最小数字 $m$ 的倍数全部删去,最后得到的便是 $2 \to n$ 内所有的素数。
int sieve(int n) {
int p = 0;
for (int i = 0; i <= n; ++i) is_prime[i] = true;
is_prime[0] = is_prime[1] = false;
for (int i = 0; i <= n; ++i) {
if (is_prime[i]) {
prime[p++] = i;
for (int j = 2 * i; j <= n; j += i) is_prime[j] = false;
}
}
return p;
}
快速幂
快速幂实际上应用了二进制优化的思想。对于 $k^m$ 有 $k^{1+2+\cdots+i=m}=k^1 \times k^2 \times \cdots \times k^i$。
int pow(int x, unsigned int m) {
int res = 1;
while (m > 0) {
if (m & 1) res *= x;
x = x * x;
m >>= 1;
}
return res;
}
Others
References