OpLog - a library for scaling update heavy data structures
背景
在 multi-core scaling read-heavy data structure 上已经有了很多有用的技术,比如 Read-copy-update。但是 update-heavy 的数据结构还鲜有通用的方案。显然,对于 update-heavy 的数据结构来说,只要在读之前,将数据准备好就行。OpLog 针对这部分场景,提出了一种通用的 scaling update-heavy data structures 实现方式。
思路
OpLog 的解决办法是为每个数据结构准备一个 per-core 的日志,写操作只需要将其追加到日志中即可。在读时,按照时间顺序合并日志并应用到数据结构上。这样的设计方式有几个好处:
- Batching updates:通过延迟执行,很多 update 操作可以直接合并,计数操作,原来的 N 次 +1 操作可以合并为一次 +N
- Absorbing updates: 比如先执行 put,之后 delete,那么无需执行任何操作
OpLog 作为一种通用的设计思路,还需要考虑到尽管某个实现需要解决 update-heavy 的问题,但是只有少数 update-heavy 的实例才会通过 OpLog 收益,多数情况下 per-core 的日志对这部分实例是一个负担。OpLog 只对最近使用过的对象设置 log,如果一个对象长期未更新,那么 OpLog 可以回收这部分空间。
struct Counter : public Object<CounterLog> {
struct IncOp : public Op {
void exec(uint64_t* v) { *v = *v + 1; }
}
struct DecOp : public Op {
void exec(uint64_t* v) { *v = *v - 1; }
}
void inc() { log(IncOp()); }
void dec() { log(DecOp()); }
uint64_t read() {
synchronize();
uint64_t r = val_;
unlock();
return r;
}
uint64_t val_;
};
struct CounterLog : public Log {
void push(Op* op) { op->exec(&val_); }
static void apply(CounterLog* qs[], Counter* c) {
for_each_log(CounterLog* q, qs)
c->val_ += q->val_;
}
uint64_t val_;
};
论文中有使用 OpLog 实现 Counter 的例子。inc 和 dec 操作生成一个 OP 并记录到 log 中,读操作需要先加锁,合并 log 并应用到 counter 上,再返回 val_。
评估
一般会认为 OpLog 的实现对 read 不友好。不过论文也做了一个 benchmark。
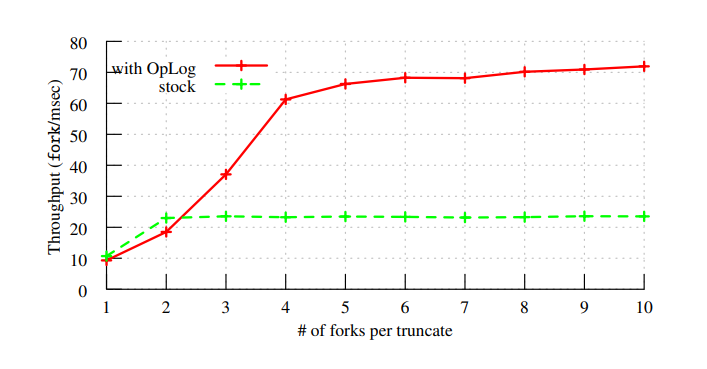
结果显示,OpLog 对一些 read periodically 的数据结构也有性能改善。