HotRing - A Hotspot Aware In-Memory Key-Value Store
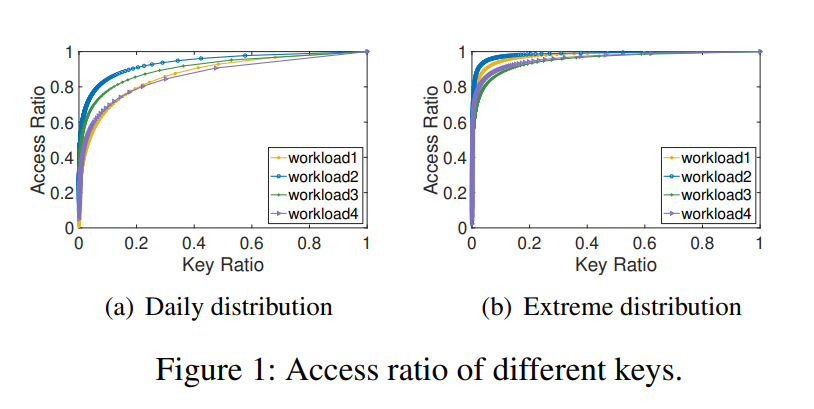
在 Alibaba 的生产环境中,KVS 的请求里有 50%-90% 只访问了 1% 的数据。如下图:
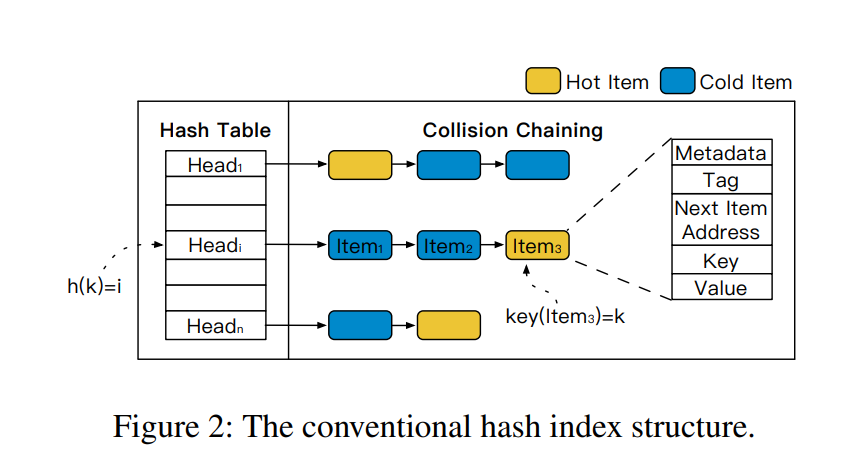
实现 KVS 有很多可用的索引结构,其中 HASH 用得最多。目前的 HASH 算法并没有优化热点访问,也就是说读取一条热点数据,所付出的代价和读取其他数据是一样的。如下图,传统 HASH INDEX 结构的热点数据可能分布在 collision chaining 的任意位置。
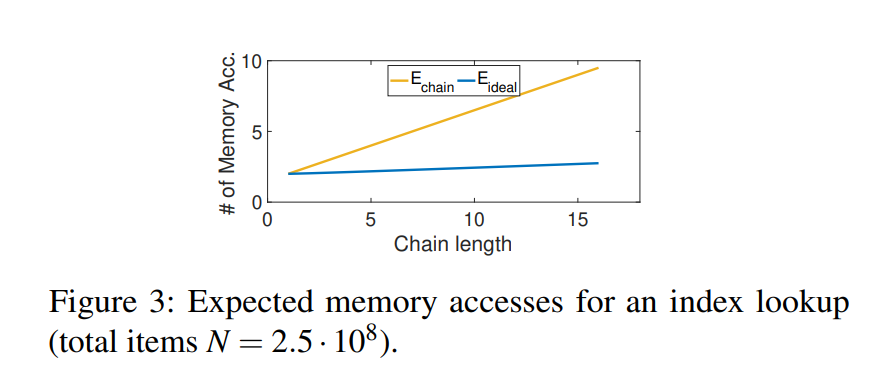
理想情况下,查找一条数据的内存访问次数应该和它的冷热层度负相关。
想要达到理想的情况,需要解决两个问题:
- 检测并适应 hotspot shift
- concurrent access
HotRing
论文的做法是:针对问题 1,将传统哈希表中的 collision chain 替换成 ordered-ring。如果热点发生迁移,那么直接将 bucket header 指向新的热点 item 即可。针对问题 2,采用 lock-free 设计。
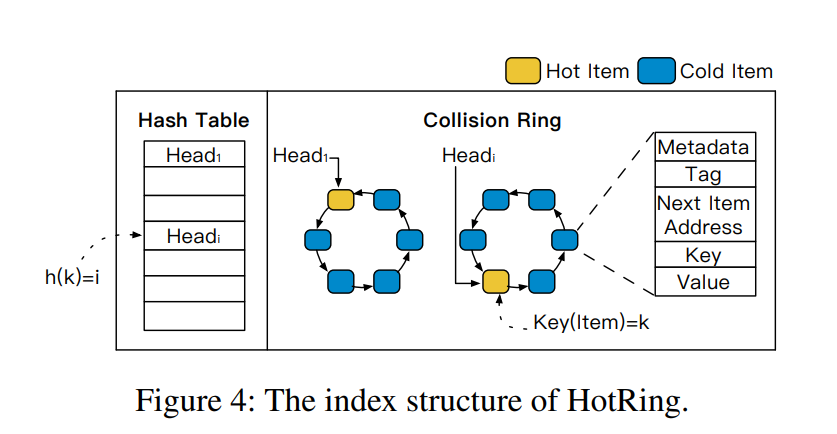
ordered ring 的结构如上图所示,整个 ring 首尾相连,一旦发现热点迁移,只需要将 bucket 的 header 更新到新热点 item 即可。这样做的好处是热点迁移时无需重新给 ring 上数据排序。
查找时从 header 开始,遍历整个 ring ;同时 Ring 上的数据会按照 <tag, key> 的顺序插入到合适的位置。这样做的目的是:
- tag 主要用来避免对 key 的比较
- 顺序则是用于查询时判断 ring 是否结束,否则查找时可能会受到并发更新操作的影响,无法判断是否已经遍历完整个 ring。

此外,排序还有另一个好处,根据 termination 条件,平均查找次数约为传统 collision chain 实现方式的一半。
Hotspot Shift Identification
由于 hash 的 strongly uniformed distribution,可以认为热点数据也分布在各个 bucket 中,热点迁移识别的工作主要在 bucket 内部。
论文提出了两种识别方式:
- random movement
- statistical sampling
第一种方式是每隔 R 个请求,如果第 R 个请求是 hot access,则不做任何改变;如果第 R 个请求是 cold access ,那么这个请求对应的 item 会成为新的 hot item。
这种方式是一个简单的概率实现,其缺点也非常明显:参数 R 的大小显著影响热点识别效果;如果数据访问频率分布是均匀的,或者 collision ring 中有多个热点,那么 head pointer 可能会频繁在这些热点中跳变;
另一种方式则是在 item 里记录下访问次数,根据次数选择出合适的 item 来作为新的 hot item。
猜想:是否可以使用 thread-local 级别的数据采样算法,来得到更为精确的数据,同时也避免了不必要的 CAS 操作?
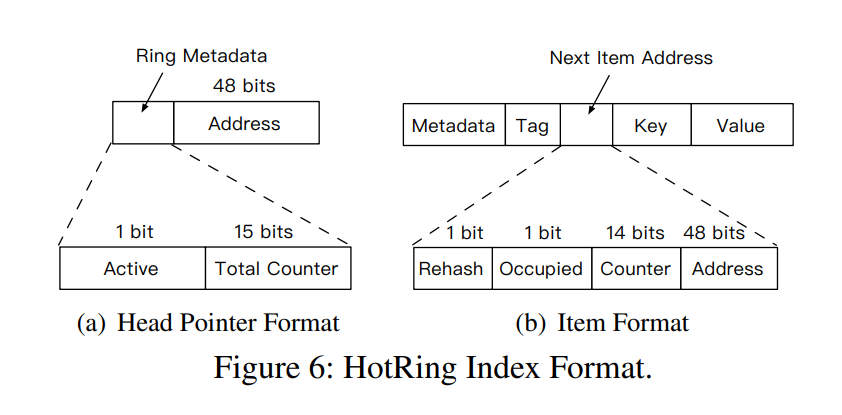
如上图所示,每个 head pointer 的前 16bits 和 item pointer 其中的 14 bits 用于存储采样信息。其中 Active 表示在这条 collision ring 上开启采样,它主要是为了进行优化:为了确保采样不对正常读写造成影响,默认情况下 Active 为 false;每 R 个请求进行一次判断,如果仍然是 hot access,则认为目前的 hot item 仍然是准确的;否则才设置 Active 为 true。一旦 Active 被设置,后续请求需要同时使用 CAS 更新 Total Counter 和 Item 的 Counter。
采样完成后,最后一个访问的线程负责计算 collision ring 上每个 item 的访问频率,并调整 hot item。(先清除 Active 的标记)
Write-Intensive Hotspot with RCU
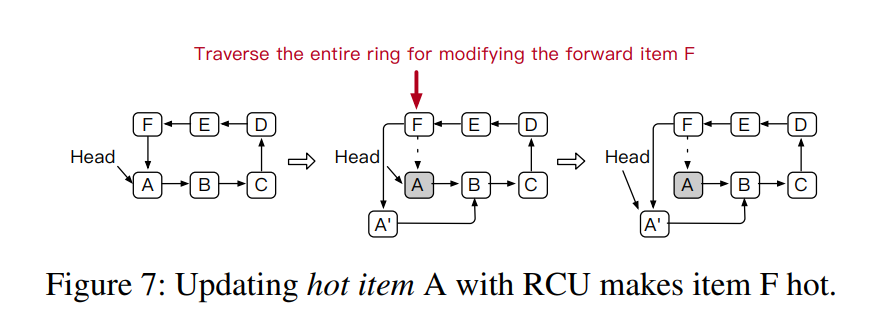
HotRing 上的 key 是通过 read-copy-update 操作进行的。更改一个 key 时,需要遍历整个 collision ring ,找到待更新的 key 的前项,并更改其指针到新 item 上。所以更新操作的 Counter 应该需要记录到 hot item 的前一项中,这样算法就会选择前一项作为 hot item,因更新操作所需要的访问次数也因此降低。
Concurrent
- read: 读操作从 head pointer 开始遍历 HotRing,直到碰到终止条件
- insert: 找到合适位置,更新前一项的 Next Item Address 即可
update 和 deletion 会复杂一些。对于 update,如果 value 在 8 字节内,可以直接通过 CAS 进行 in-place 更新。否则,需要使用两阶段提交的策略来避免异常。
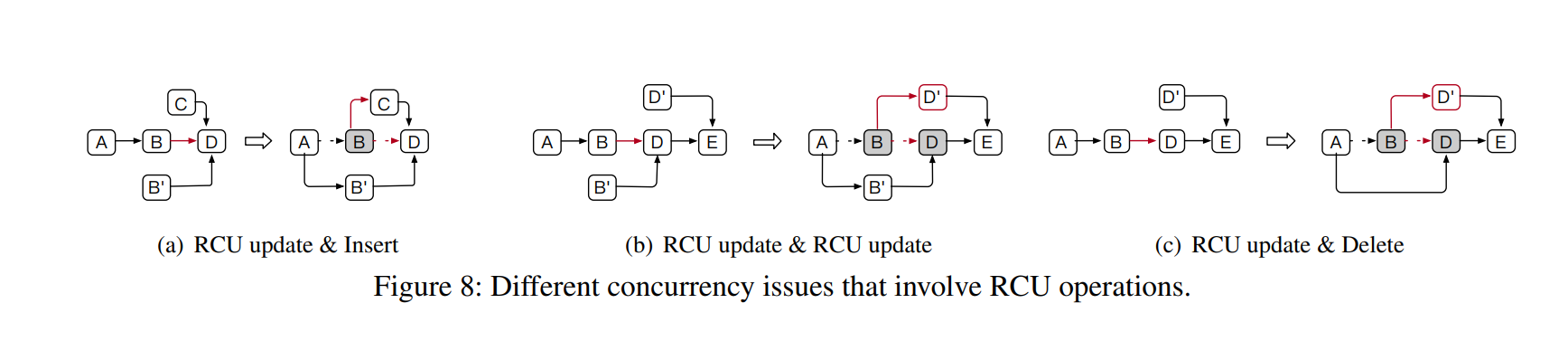
如果 read-copy-update 和其他更新操作同时执行,就会上图所示的异常。以 RCU Update & Insert 为例,由于 update B 和 insert C 同时进行,C 负责更新 B 的 Next Item Address,而此时 B’ 更新了 A 的 Next Item Address,最终 C 丢失,无法被访问。
解决方式是在 update\delete 某个 item 时,先标记上 Occupied bit,这样其他尝试更新该 Next Item Address 的请求会失败并进行重试,所以后续对这个 Item 进行的操作就是安全的。
Head Pointer Movement
head pointer 同样也会受到并发操作的影响,主要有两种情况:
- 热点迁移导致的 head pointer 更新
- 其他 update 和 deletion 操作
对于 case 1,head pointer 在迁移前,需要设置新 hot item 为 Occupied 保证这个过程中该节点不会被 update 或 delete。
对于 update head pointer 指向的 item,只需要在替换时设置上新 item 的 Occupied 即可;对于 delete head pointer 指向的 item,还需要设置 head pointer 指向的新 item 的 Occupied。
Lock free Rehash
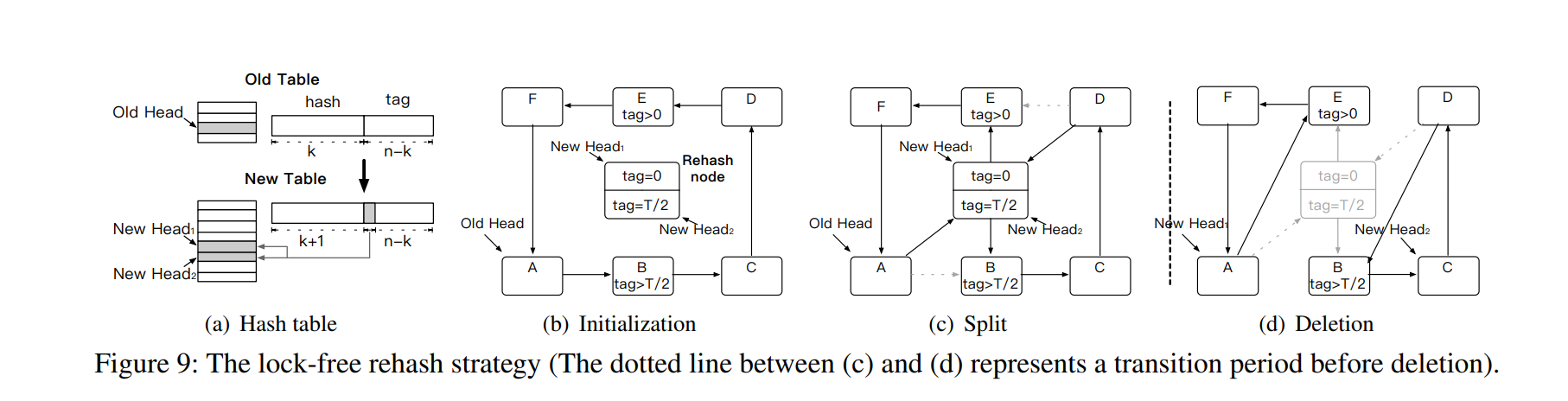
传统的 Hash Table 使用 load factor 来出发 rehash,这个过程显然没有考虑到 hotspot 的影响。HotRing 使用 access overhead 来出发 rehash。
由于 HotRing 是有序的,rehash 时只需要从中间某个位置断开,生成两个新的 HotRing 即可。这个阶段主要分为三步:
评估
略