Achieving High Throughput and Elasticity in a Large-than-Memory Store
背景
如果数据都来自同一台机器,那么可以用导入、索引数据达到 100Mops/s 的单机 multi-core key-value stores 处理。而实际上现在有数十亿的数据需要处理,所以数据必须经过网络传输,并通过云的弹性能力创建足够的实例进行服务。为了满足这个需求,Shadowfax 在 FASTER 的基础上,构建了一个具有快速数据迁移能力的高性能分布式 key-value store。
基本设计
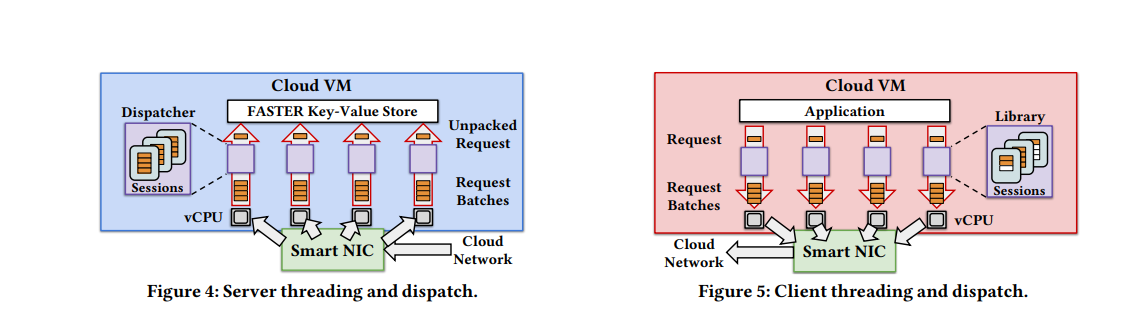
Per core per thread but Shared Everthing
Shadowfox 的设计目标是能够充分利用 CPU 资源,提高系统吞吐。减少核间通信、竞争是提高 CPU 资源的关键。
一种可行的方式是 shared nothing,每个 thread 有一个单独的 FASTER 实例,实例间互不影响。这需要路由请求到与之对应的 FASTER 线程上去,仍然不能避免跨线程协调。一个改进的方式是每个 client 和每个 server thread 都建立连接,将路由的工作交给 client 完成。但是这也要求 client 做跨线程协调,同时让连接数量暴涨。
Shadowfox 采用的则是 shared everthing 的方式,每个线程共享一个 FASTER 实例。FASTER 提供了一种延迟通信的机制,使得它在多核下仍能取得非常高的并发。每个 client 和一个指定的 server thread 建立 session,这个 thread 负责处理该 client 的所有请求。
另外一个需要考虑的是网络部分。网络收发包需要消耗大量的 CPU 资源。Shadowfox 通过将网络请求 offload 到智能卡处理,节省出来的 CPU 资源用于提升吞吐。
这样设计的好处是:
- 避免竞争。同一个 client 的请求(来自相同 session)由同一个 thread 处理,不需要跨线程协调。
- 充分 batch,提高 pipeline。同一个 session 的请求可以充分 batch,以减少 per-packet 的开销。
- client 异步提交请求,避免 head-of-line blocking。因为 Shadowfox 随时会发生 reconfiguration,而 session 中的请求是有序的,发生 reconfiguration 时 client 能够知道哪些 request 一定失败。
Hash partition and View number
Shadowfox 将数据通过 hash range 划分的方式分布到不同的 server 中。每个 server 负责服务一个 hash range。为了识别出 reconfiguration,每个 server 为当前的 hash range 计数(view number),每次 reconfiguration 发生时递增。
view number 需要和 reconfiguration 一起持久化到 meta server 中。
view number 的好处:
- 检查请求范围时只需要比较 view number 即可,不需要依次对比请求。
- 允许进行异步、延迟执行的 record ownership change。
第二项时通过 asynchronous global cut 实现的。所谓 asynchronous global cut,其实只是通过 epoch based protection 异步地更新 view number,并将这个变化通过 session 异步地传播给 client。这个方式非常简单,无需多说,但是要取得论文中提到的保证同一时间没有任何两个 server 服务相同区间,还需要 migration 机制参与。
This cut unambiguously ensures no two servers concurrently serve operations on an overlapping hash range. This approach is free of synchronous coordination, helping maintain high throughput.
Migration
Migration 机制可以看作两阶段提交,首先 source 发送 PrepForTransfer RPC 给 target,通知 target block 所有更大 view number 的请求。等这阶段完成后,source 就提升自己的 view number,并等待所有线程同步变更(一旦线程知道 view number 提升了,就会拒绝 staled request,交由 client 重试)。所有线程的 view number 一致后,就进入下一阶段,source 发送 TransferedOwnership RPC 给 target,这个时候 target 就开始服务请求了。
Shadowfox 的 migration 可以分为两个阶段,正如上文所述,需要先通过提升 view number 完成 record ownership transfer,此后再异步地传输数据给 target。
异步传输期间,尽管 target 已经拿到 ownership,在 source 同步这部分 record 给 target 前,它都不能服务这部分数据。
这中间显然有一个 gap,怎么看都不是异步的。。。
当然,Shadowfox 为了减小这个 gap,会在开始 migration 前,对请求做一个 sampling,并将涉及到的 hot records 附带在 TransferedOwnership RPC 中一并发送给 target。这样 target 就能尽快的为 hot records 提供服务。
等到所有 record 都同步完成,migration 就算结束。整个过程可以组成一个状态机,如下图:
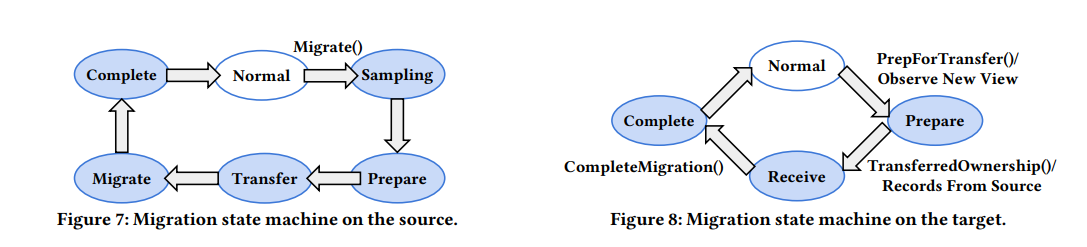
一部分 record 可能没有在内存中,在 SSD 里,Shadowfox 可以将这部分 record 写到共享存储上,这样 target 就可以直接读取这部分 record 而不是等 source 复制给它。
Fault tolerance
为了保证容错,source 和 target 在标记 complete 前,需要创建一份 checkpoint,如果之后任何一台机器故障,都可以通过 checkpoint 恢复数据。如果时在迁移过程中发生了故障,则 shadowfox 会取消迁移操作,并将迁移涉及到的 hash range 迁移回 source。
如果某个机器不可用,shadowfox 需要从这条机器撤销其 record 的所有权,这是通过 lease 完成的。
评估
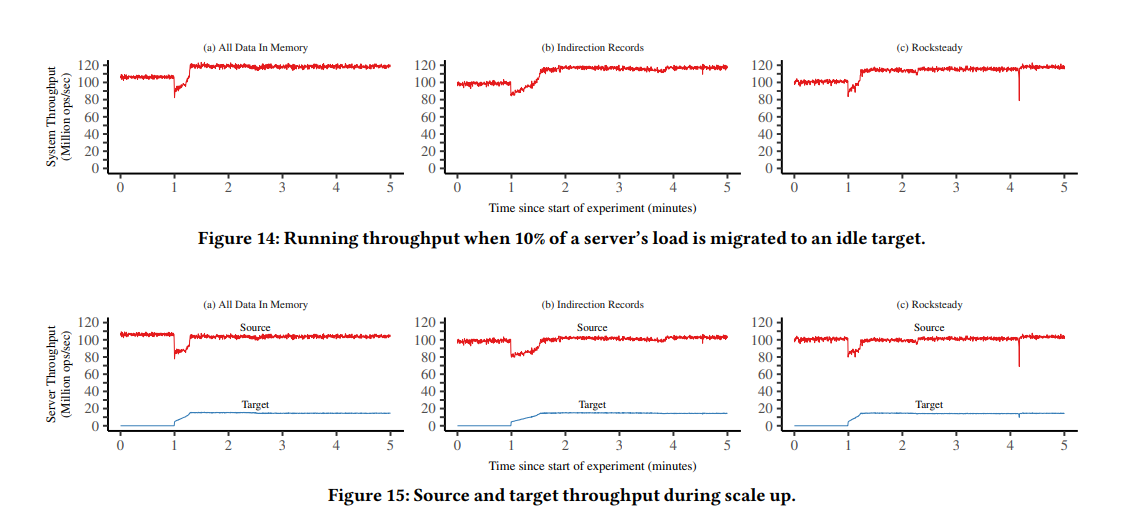
看起来 migrate 和 scale up 仍然对 throughput 有较大影响。
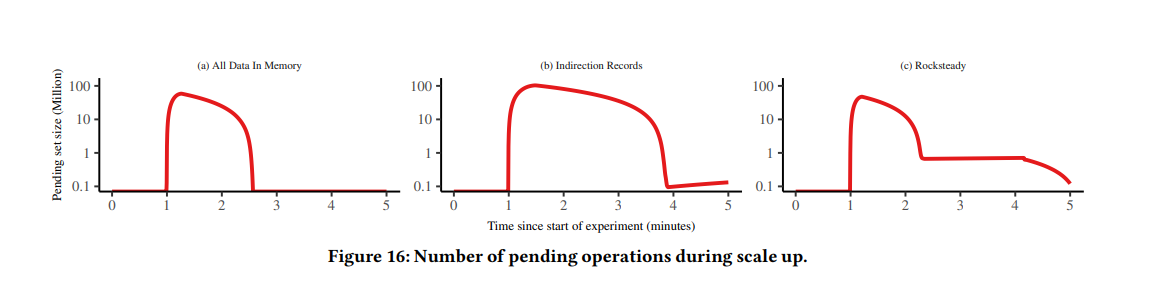
同时看起来在迁移过程中,被 block 的请求数量也不少。